7 Arten von Simulationsfehlern bei Tests autonomer Fahrzeuge und wie man sie beheben kann
Automobilindustrie
08 / 06 / 2025

Jeder ins Stocken geratene Prototyp fühlt sich wie eine verpasste Chance an, wenn es darum geht,selbstfahrende Technologien sicher zu machen. Programmmeilensteine geraten außer Reichweite, das Vertrauen in die Finanzierung wackelt, und Ingenieur:innen ringen um Erklärungen, warum der Prüfstand nicht mit den Entwurfsiterationen Schritt halten kann. Man spürt den Druck von Managern, die einen Beweis dafür brauchen, dass die Wahrnehmungsalgorithmen einen Fußgänger nicht falsch klassifizieren, sobald das Auto das Testgelände verlässt. In diesem Moment entscheiden die Simulationsqualität und die Testorchestrierung darüber, ob Ihr nächster Bericht Fortschritte oder Verzögerungen aufzeigt.
Die Zeitpläne werden immer enger, aber die Komplexität der heutigen Fahrzeugsensorik nimmt weiter zu, da Radar, Lidar, Kameras und Hochleistungsrechner in eine anfällige Pipeline eingebunden werden. Eine unerwartete Störung innerhalb dieser Pipeline kann einen einwöchigen Regressionszyklus in eine dreiwöchige Übung verwandeln. Teams, die diese Komplexität in den Griff bekommen, sichern sich schnellere Freigaben, gewinnen Budgetspielraum zurück und steigern ihre Glaubwürdigkeit bei den Behörden. Die anderen fügen so lange Patches hinzu, bis ihre Testmatrix unüberschaubar wird.
Die Qualität der Simulationen und die Orchestrierung der Tests entscheiden darüber, ob Ihr nächster Bericht Fortschritte oder Verzögerungen aufzeigt.

Häufige Ursachen für Tests bei der Validierung autonomer Fahrzeuge
Sensor-Fusion-Stacks, funktionale Sicherheits-Workflows und Cybersicherheits-Prüfungen greifen alle auf denselben begrenzten Pool von hardware(HIL)-Rigs zurück. Dieses Gedränge führt zu Reibungsverlusten bei der Zeitplanung, die sich in größeren Programmverzögerungen niederschlagen und die Herausforderungen bei den Tests und der Validierung autonomer Fahrzeuge offenlegen , die viele Entwicklungsteams plagen. Jedes Mal, wenn ein zu prüfendes System auf den Prüfstand wartet, riskieren die Ingenieur:innen , den Kontext zu verlieren, was zu Nacharbeit und doppelter Fehlersuche führt. Selbst wenn der Prüfstand verfügbar ist, vergeudet die manuelle Neukonfiguration oft einen halben Tag, bevor ein einziges Szenario ausgeführt werden kann.
Die Testdynamik lässt weiter nach, wenn die Modelltreue hinter den Konstruktionsänderungen zurückbleibt. Die Sensoremulation mit niedriger Auflösung verbirgt Defekte bis zu den Spurtests und verursacht teure Nacharbeiten. Dateiübertragungen zwischen Desktop-Design-Tools und HIL-Speicher können Stunden in Anspruch nehmen und machen Regressionsläufe über Nacht unmöglich. Wenn dann noch Governance-Anforderungen für die Rückverfolgbarkeit über Tausende von Szenarien hinzukommen, wird die Warteschlange länger als der Sprint selbst.
7 häufige Simulationsherausforderungen bei Projekten zum autonomen Fahren
Präzise und rechtzeitige Validierung trennt Konzeptfahrzeuge von Serienfahrzeugen. Ingenieur:innen stehen unter dem wachsenden Druck von Sicherheitsbehörden, Investoren und der öffentlichen Meinung, die alle einen glaubwürdigen Beweis dafür verlangen, dass die Funktionen Autonome Systeme im komplexen Verkehr funktionieren. Simulationen versprechen eine nahezu unbegrenzte Kilometerleistung ohne physische Prototypen, doch ihre Effektivität bricht zusammen, wenn Pipelines, Modelle oder Datenmanagement aus dem Gleichgewicht geraten. Ein genauerer Blick auf diese Brüche zeigt die hartnäckigsten Hindernisse und wie disziplinierte Arbeitsabläufe sie effizient beseitigen.
1. Unvollständige oder wenig realitätsnahe Modelle verringern die Testabdeckung
Wahrnehmungsmodelle im Frühstadium beruhen oft auf vereinfachten Kinematiken oder allgemeinen Sensorfehlerprofilen. Diese Abkürzungen fühlen sich akzeptabel an, bis es bei Versuchen auf einer geschlossenen Strecke zu Abstürzen kommt, die zu Notkorrekturen zwingen, die von der geplanten Arbeit an den Funktionen ablenken. Hochauflösende Geländenetze, detaillierte Radarquerschnitte und wetterabhängige Rauschschichten unterstützen Aufdeckung von stillen Fehlern, bevor die Zeit auf der Strecke beginnt. Die Beibehaltung dieser Genauigkeit über mehrere Anbieter hinweg erweist sich jedoch als schwierig, wenn die Dateiformate und Versionsverwaltungspraktiken voneinander abweichen.
Simulationsdatensätze altern schnell, wenn sich Konstruktionsparameter ändern, was zu irreführenden Zuverlässigkeitsmetriken führt. Teams, die automatisierte Modellvalidierungspipelines einsetzen, erkennen veraltete Daten, bevor die nächtlichen Builds beginnen, und bewahren so das Vertrauen in wichtige Leistungsindikatoren. Klare Eigentumsgrenzen und modulare Schnittstellenspezifikationen verringern die Reibung zwischen System-of-Systems-Mitwirkenden. Investitionen in die Skalierbar der Speicherung mit robusten Metadaten-Tags halten die Abrufzeiten niedrig, ohne die Granularität zu beeinträchtigen.
2. Probleme bei der Toolchain-Integration verursachen Testinstabilität
Skripting Glue, das Closed-Source-Physik-Engines, benutzerdefinierte Middleware und Sicherheitsmonitore verbindet, verbirgt oft subtile Latenzspitzen. Diese Spitzen führen zu nicht-deterministischem Verhalten in Closed-Loop-Läufen und untergraben das Vertrauen in die zeitabhängige Steuerungslogik. Ingenieur:innen verbrauchen wertvolle Tage damit, einen obskuren Pufferüberlauf zu isolieren, anstatt Abdeckungsdaten zu sammeln. Eine disziplinierte Integrationsstrategie, die auf offenen Anwendungsprogrammierschnittstellen (APIs) und Code-Linting basiert, verhindert, dass sich diese Störungen über Sprints hinweg ausbreiten.
Wenn Versionsabweichungen auftreten, stellen deterministische Rollback-Prozeduren innerhalb von Minuten statt Stunden einen bekannten, guten Ausgangszustand wieder her. Kontinuierliche Integrationsserver, die jeden Code-Push kompilieren, bereitstellen und einem Smoke-Test unterziehen, erkennen Abhängigkeitskonflikte, bevor eine formale Kampagne beginnt. Gemeinsame Protokollierungsschemata vereinfachen die Triage, indem sie Zeitstempel und Sensorkennungen über Subsysteme hinweg angleichen. Das Ergebnis ist ein wiederholbarer, nachvollziehbarer Testablauf, der sowohl internen Audits als auch externen Zertifizierungsstellen genügt.
3. Bei der Erstellung von Szenarien fehlt die Vielfalt der Vorteil
Szenariobibliotheken tendieren oft zu komfortablen Fahrbedingungen, da die Datensammler ihre Fahrzeuge bei schlechtem Wetter abstellen. Das Fehlen von Nebel, Schneetreiben oder untypischen Baustellenschildern führt dazu, dass die Wahrnehmungsalgorithmen gefährlich unzureichend trainiert sind. Synthetische Szenario-Generatoren versprechen Abwechslung, doch durch naive Zufallsgenerierung werden sicherheitskritische Situationen wie ungeschütztes Linksabbiegen an Steigungen übersehen. Ingenieur:innen erhöhen die sinnvolle Vielfalt, indem sie eine risikobasierte Gewichtung anwenden, die sich auf Versicherungsansprüche und Unfalldatenbanken stützt.
Sobald die Prioritätsbedingungen definiert sind, werden Geschwindigkeit, Positionierung und Verkehrsdichte durch parametrisierte Vorlagen systematisch verändert, wodurch die Abdeckung vervielfacht wird, ohne dass der Speicherplatz aufgebläht wird. Human-Review-Gates kennzeichnen visuell unplausible Szenen, die sonst unnötig Simulationszyklen verbrauchen würden. Im Laufe der Zeit heben Analyse-Dashboards Szenariocluster mit anhaltend hohen Fehlerquoten hervor und leiten gezielte Verbesserungen anstelle von punktuellen Anpassungen an. Diese Feedback-Schleife hält die Szenariobibliotheken schlank und dennoch leistungsstark.
4. Begrenzte hardwareverlangsamt Iteration
Ein einziges HIL-Rack kann Hunderttausende von Dollar kosten, was die Budgetverantwortlichen dazu verleitet, den Einsatz zu begrenzen. Wenn sich die Zahl der Entwicklungsteams vervielfacht, wächst der Wettbewerb um die Prüfstandszeit in direktem Verhältnis zum Rückstand. Remote-Queuing hilft, aber Latenzzeiten und Sicherheitshürden begrenzen die Durchsatzsteigerung. Virtuelle HIL-Instanzen, die auf FPGA-Ressourcen ( Field-Programmable Gate Array ) in der Cloud ausgeführt werden, bieten Elastizität, doch Nacharbeiten bei Integrationstests verzögern oft die Einführung.
Erfolgreiche Programme unterteilen Arbeitslasten in deterministische Low-Level-Kontrollschleifen, die auf physischen FPGA-Karten ausgeführt werden müssen, und in Arbeitslasten mit höherer Latenz, die auf virtualisierte Rechenleistung migriert werden können. Die in den Orchestrierungsskripten kodierten Zuweisungsregeln halten Echtzeittermine ein und maximieren gleichzeitig die Gleichzeitigkeit. Ingenieur:innen schalten dann kurzlebige Cloud-Replikate für Regressionsprüfungen frei, so dass die Vor-Ort-Anlagen für die kritische Endabnahme frei sind. Kostenverfolgungs-Dashboards, die mit Kontocodes verknüpft sind, sorgen dafür, dass sich die Finanzteams mit der Pay-as-you-go-Nutzung wohl fühlen.
5. Echtzeitsimulation ist unter komplexen Bedingungen unzureichend
Autonome Systeme Versuche sind aufgrund der dichten Sensornetze, der physikbasierten Fahrzeugdynamik und der Wettermodelle hoher Ordnung sehr rechenintensiv. Wenn die Rahmenzeiten die Toleranzen im Millisekundenbereich überschreiten, destabilisieren sich die Regelkreise, was zu falsch-negativen Ergebnissen führt, die unnötige Debugging-Zyklen verursachen. FPGA-Beschleunigung mindert dieses Risiko, doch die Partitionierung von Befehlen auf heterogene Verarbeitungseinheiten erfordert besondere Fähigkeiten. Ingenieur:innen beschleunigen das Onboarding durch die Übernahme von Referenzdesigns, die Rechenkerne automatisch auf geeignetes Silizium abbilden.
In den Simulationsstack integrierte Tools zur Leistungsprofilerstellung zeigen Hotspots an, lange bevor sie die Einhaltung des Zeitplans gefährden. Adaptive LOD-Algorithmen (Level-of-Detail) verkleinern periphere Szenerien, während die kritische Präzision im Vordergrund erhalten bleibt. Regelmäßige Stresstest-Kampagnen zeichnen Worst-Case-Matrixgrößen auf und übertragen diese Metriken in Dashboards für die Ressourcenplanung. Diese Praktiken halten die Frame-Zeiten stabil und unterstützen die kontinuierliche Integration neuer Sensormodelle und Algorithmus-Updates.
6. Herausforderungen beim Datenmanagement beeinträchtigen Rückverfolgbarkeit und Wiederholbarkeit
Petabytes an Lidar-Punktwolken, hochauflösenden Karten und Telemetrieprotokollen erdrücken Ad-hoc-Ordnerstrukturen. Wenn die Namenskonventionen abdriften, haben Ingenieur:innen Mühe, eine Regression zu ihrer ursprünglichen Szenariodefinition zurückzuverfolgen. Audit-Anforderungen für funktionale Sicherheitszertifizierungen verschlimmern das Problem noch, da jeder Datensatz spezifischen Anforderungen und Bestanden-/Nichtbestanden-Kriterien entsprechen muss. Die Einführung von versionskontrollierten Objektspeichern mit unveränderlichen Datensatzkennungen verhindert stillschweigende Überschreibungen, die Compliance-Prüfungen zum Scheitern bringen.
Petabytes an Lidar-Punktwolken, hochauflösenden Karten und Telemetrieprotokollen überfordern die Ad-hoc-Ordnerstrukturen.
Die automatische Erfassung von Metadaten kennzeichnet jedes Simulationsartefakt mit Parameter-Hashes, software und hardware . Abfrage-Engines, die auf diesen Tags aufbauen, liefern Provenance Chains in Sekundenschnelle und unterstützen so Ursachenanalysen und Rückrufuntersuchungen. Rollenbasierte Zugriffskontrollen schützen sensible Daten und ermöglichen eine nahtlose Zusammenarbeit zwischen weltweit verteilten Teams. Zusammen fördern diese Verfahren das Vertrauen, dass jede Kennzahl auf dem Dashboard die korrekten Eingabebedingungen widerspiegelt.
7. Zeitaufwendige Einrichtung und Neukonfiguration von Prüfständen
Handverdrahtete Sensorkabel, manuelle Stromzufuhr und tabellengesteuerte Konfigurationsschritte zwingen Ingenieur:innen dazu, zwischen den Durchläufen im Leerlauf zu bleiben. Ein einziger falsch sitzender Stecker kann eine Nachtcharge zum Scheitern bringen und wertvolles Tageslicht für Wiederholungen verbrauchen. Die Automatisierung der Prüfstandsorganisation durch skriptgesteuerte Gerätekonfiguration und digitale Zwillingsausrichtung verwandelt stundenlanges Herumprobieren in Minuten wiederholbarer Routine. Durch das modulare Design der Vorrichtungen wird die physische Nacharbeit weiter reduziert, da die Mitarbeiter die Wahrnehmungsstapel austauschen können, ohne die Subsysteme der Fahrzeugdynamik zu stören.
Configuration-as-code-Repositories erfassen jeden Setup-Parameter, von Sensor-Bias-Tabellen bis hin zu FPGA-Bitstream-Versionen. Continuous-Deployment-Frameworks übertragen diese Konfigurationen an HIL-Controller und validieren die Integrität der Prüfsummen, bevor die Ausführung beginnt. Wenn eine neue hardware eintrifft, aktualisieren die Ingenieur:innen ein YAML-Manifest, anstatt mehrere Tabellen zu bearbeiten, und bewahren so das institutionelle Wissen innerhalb der Versionskontrolle. Vorhersehbare Hochlaufzeiten stellen das Vertrauen wieder her, dass jeder Sprint mit validierten Ergebnissen endet, anstatt mit verbleibenden Zweifeln.
Die technischen Vorteile, die sich aus der Lösung dieser Herausforderungendes autonomen Fahrens ergeben , reichen weit über das Labor hinaus. Kürzere Regressionszyklen ermöglichen es den Teams, sich auf die Innovation von Funktionen zu konzentrieren, statt auf die Brandbekämpfung. Verbesserte Rückverfolgbarkeit stärkt die Sicherheit bei der Einreichung von Zulassungsanträgen, beschleunigt die Markteinführung und stärkt den Ruf der Marke. Die Vorhersehbarkeit der Kosten verbessert die Kapitalplanung und unterstützt strategische Entscheidungen über Investitionen in Plattformen und Personal.
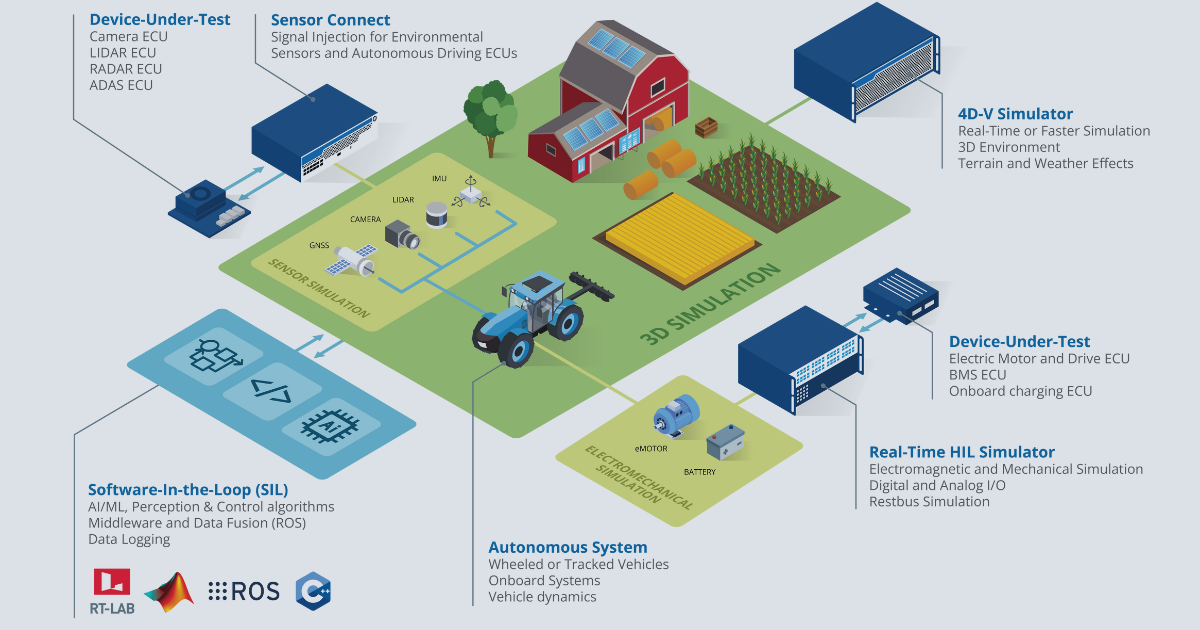
Wie werden autonome Fahrzeuge mit Echtzeit-Simulationswerkzeugen getestet?
Die Projektteams beginnen die Entwicklung von Prüfständen mit der Auswahl deterministischer Ausführungsmaschinen, die in der Lage sind, Physik, Sensoremulation und software innerhalb strenger Zeitvorgaben zu synchronisieren. Hardwarebeherbergen elektronische Steuergeräte (ECUs) und Wahrnehmungsbeschleuniger, während feldprogrammierbare Gate-Arrays Fristen im Sub-Millisekundenbereich erzwingen. Praktiker, die sich fragen, wie autonome Fahrzeuge getestet werden, erkennen schnell, dass offene Schnittstellen ebenso wichtig sind wie die reine Rechenleistung, da modellbasierte Entwurfswerkzeuge die Artefakte ohne Datenverlust weitergeben müssen. Standardisierte FMI-Pakete (Functional Mock-up Interface) und ROS-2-Brücken (Robot Operating System) sorgen für eine saubere Übergabe und ermöglichen es heterogenen Subsystemen, Simulationszeitstempel gemeinsam zu nutzen.
Während der Ausführung übermitteln Szenarioserver digitale Straßennetze, Verkehrsagenten und Wetterparameter an den Simulationskern. Synthetische Sensordaten werden über Low-Level-Treiber an die eigentliche Steuergeräte-Firmware weitergeleitet, um denselben Stack zu testen, der auch für die Serienproduktion vorgesehen ist. Die Hochgeschwindigkeitsprotokollierung erfasst Rohsignale und Algorithmusentscheidungen und speist Analyse-Dashboards, die die Ergebnisse mit wichtigen Sicherheitsindikatoren vergleichen. Ingenieur:innen Verfeinern dann Wahrnehmungsschwellen, Regelverstärkungen oder Fehlerbehandlungslogik und spielen identische Szenarien innerhalb von Minuten nach, um Korrekturen festzulegen, bevor die Budgets für physische Prototypen aufgebläht werden.
Wie OPAL-RT hilft, die Herausforderungen bei Tests und Validierung autonomer Fahrzeuge zu lösen
OPAL-RT bietet hochpräzise Echtzeit-Simulationsplattformen mit geringer Latenz für Ingenieur:innen , die keine Kompromisse bei der Zeitgenauigkeit oder der offenen Architektur eingehen wollen. Unsere modulare hardware kann sowohl CPU- als auch FPGA-zentrierte Arbeitslasten aufnehmen, so dass Sie die Rechenressourcen jedem Subsystem zuordnen können, ohne Rack-Platz oder Kapital zu verschwenden. Die software vereint MATLAB/Simulink-, FMI/FMU- und Python-Assets in einem einzigen Scheduling-Kernel, sodass Sie Modelle ohne Formatierungsaufwand zwischen Desktop-Design und hardwareübertragen können. Integrierte Überwachungswerkzeuge zeigen Timing-Überschreitungen sofort an und geben Ihrem Team einen klaren Einblick in Engpässe, bevor diese die Sicherheitsziele gefährden. Die Lizenzierung bleibt Flexibel, so dass die Projektleiter ihre Ausgaben an den Sprint-Zielen ausrichten können, statt sich zum Kauf fester Kapazitäten zu verpflichten.
Neben der Leistungsfähigkeit bieten OPAL-RT Plattformen auch Sicherheit für Tests und Validierungsprogramme für autonome Fahrzeuge. Unveränderliche Szenario-Identifikatoren, automatische Metadatenerfassung und rollenbasierte Zugriffskontrollen genügen strengen Audits der funktionalen Sicherheit. Native Unterstützung für Cloud-Burst-Ausführung erweitert die HIL-Kapazität während Regressionsbursts, während sich lokale Bänke auf abschließende Sign-off-Läufe konzentrieren. Zu den Mitarbeitern des globalen Supports gehören ehemalige Ingenieur:innen , die sich mit Ihnen im Labor oder online treffen, um die Diagnosezyklen zu verkürzen und den Schwung zu erhalten. Sie können sich darauf verlassen, dass OPAL-RT in jeder Phase der Entwicklung vonAutonome Systeme für Genauigkeit, Budgetdisziplin und Termintreue sorgt.
Allgemeine Fragen
Was sind die größten Engpässe in den Arbeitsabläufen bei Tests autonomer Fahrzeuge?
Testinstabilität, Lücken in der Szenarienerstellung und Datenverarbeitung verlangsamen die Validierungszyklen. Teams kämpfen oft mit unvollständigen Modellen, langsamer HIL-Einrichtung und fehlender Vorteil . Diese Probleme verlängern die Entwicklungszeiten und verringern das Vertrauen in die software . Um diese Probleme zu lösen, sind High-Fidelity-Simulationswerkzeuge, offene Integrations-Frameworks und eine Skalierbar Infrastruktur erforderlich. OPAL-RT bietet Echtzeit-Simulationsplattformen, die die Beseitigung dieser Hindernisse unterstützen und die Validierung mit Präzision beschleunigen.
Wie kann ich die Testabdeckung für Vorteil in Projekten für autonomes Fahren verbessern?
Eine Erweiterung der Testabdeckung bedeutet, dass man über die üblichen Verkehrsszenarien hinausgeht und Situationen mit hohem Risiko und geringer Häufigkeit wie Baustellen, schlechtes Wetter oder Sensorstörungen einbezieht. Teams können die Variation durch parametrisierte Vorlagen und risikobasierte Gewichtung auf der Grundlage realer Unfalldaten erhöhen. Szenarienvielfalt ist der Schlüssel zum Aufbau robuster Wahrnehmungs- und Kontrollsysteme. OPAL-RT unterstützt eine realitätsnahe Emulation mit anpassbaren Szenario-Injektionstools, um Ihre Abdeckung mit messbarer Kontrolle zu verbessern.
Warum verlangsamen sich die Tests beim Scale-up?
Die HIL-Testkapazität stößt oft an ihre Grenzen, wenn Teams eine begrenzte Anzahl von Prüfständen für mehrere Projekte gemeinsam nutzen. Ohne Skalierbar Infrastruktur oder virtuelle Optionen sind Tests unvermeidlich. Cloud-basierte Bereitstellungen und die Partitionierung von Arbeitslasten über physische und virtuelle Ressourcen sind von entscheidender Bedeutung. OPAL-RT bietet Flexibel Bereitstellungsoptionen, die unterstützen Durchsatz erhöhen, ohne die Echtzeitbedingungen zu beeinträchtigen, so dass Sie ohne Qualitätseinbußen skalieren können.
Wie kann ich Wiederholbarkeit und Rückverfolgbarkeit über meine Simulationsläufe hinweg sicherstellen?
Die Verwaltung von Terabytes an Sensordaten und Testergebnissen wird ohne eine strukturierte Datenstrategie schwierig. Versionierte Artefakte, Metadaten-Tagging und Configuration-as-Code-Verfahren sind notwendig, um jeden Test mit seinen Parametern zu verknüpfen. Diese Klarheit unterstützt die Nachvollziehbarkeit und die interne QS. Die OPAL-RT Plattform erfasst die vollständige Datenprovenienz und Szenario-Metadaten, um unterstützen Teams bei der Einhaltung der Zertifizierungsstandards unterstützen und gleichzeitig die betriebliche Agilität zu erhalten.
Wie werden Simulationswerkzeuge zur Validierung autonomer Fahrzeuge eingesetzt?
Echtzeit-Simulationswerkzeuge replizieren Sensor-und Datenfusion, Straßennetze und Systemdynamik, um autonome Fahrzeugsysteme unter kontrollierten Bedingungen zu testen. Diese Tools müssen mit der tatsächlichen hardware interagieren und die Arbeitslasten der Produktion widerspiegeln, um ein genaues Leistungsfeedback zu geben. Realismus, zeitliche Präzision und Offenheit für Modelle von Drittanbietern sind von entscheidender Bedeutung. OPAL-RT bietet alle drei Eigenschaften durch seine FPGA/CPU-Hybridsimulatoren, die es Ihnen ermöglichen, schneller zu iterieren und sicher zu validieren.
Echtzeitlösungen für alle Branchen
Entdecken Sie, wie OPAL-RT die weltweit fortschrittlichsten Branchen verändert.

Microgrid
20. Mai 2026
Netzbildende vs. netzfolgende Wechselrichter und warum dieser Unterschied für Ingenieur:innen von Bedeutung ist
In diesem Leitfaden wird erläutert, wie sich netzbildende und netzfolgende Wechselrichter hinsichtlich ihres Verhaltens als Energiequelle, ihres Fehlerverhaltens, der Frequenzunterstützung, Tests und der Relaiskoordination unterscheiden.

Energiesysteme
19.05.2026
GOOSE-Nachrichten nach IEC 61850 und deren Prüfung bei Projekten zur Umspannwerksautomatisierung
Ein praktischer Leitfaden zu GOOSE-Nachrichten nach IEC 61850, Latenzzielen, Interoperabilitätsprüfungen, Testtools und der besonderen Rolle von DNP3 in der Umspannwerksautomatisierung.

Microgrid, Energie
18.05.2026
Tests Batterie-Energiespeichersysteme, Tests Netzbetreiber vertrauen
In diesem Artikel wird erläutert, wie Energieversorger ein Batterie-Energiespeichersystem anhand von Abnahmekriterien, Tests, Inbetriebnahme, Schutzprüfungen, Dauerprüfungen und nachvollziehbaren Nachweisen validieren.
EXata CPS wurde speziell für die Echtzeit-Performance entwickelt, um Studien von Cyberangriffen auf Energiesysteme über die Kommunikationsnetzwerkschicht beliebiger Größe und mit einer beliebigen Anzahl von Geräten für HIL- und PHIL-Simulationen zu ermöglichen. Es handelt sich um ein Toolkit für die diskrete Ereignissimulation, das alle inhärenten physikalischen Eigenschaften berücksichtigt, die sich auf das Verhalten des (drahtgebundenen oder drahtlosen) Netzwerks auswirken werden.