Gestion de la commutation à haute fréquence dans la simulation EMT en temps réel
Applications industrielles, Simulation
31 mars 2026

Principaux enseignements
- La commutation à haute fréquence fait passer le choix de l'architecture avant celui du solveur ; ainsi, les sections de conversion rapide doivent être implémentées sur un FPGA dès que les erreurs de synchronisation commencent à altérer le comportement.
- Les ressources du processeur restent précieuses pour les structures électriques de grande envergure et les sous-systèmes plus lents, en particulier lorsque le partitionnement et l'exécution à plusieurs débits sont gérés avec soin.
- L'exécution hybride est plus efficace lorsque l'on affecte chaque sous-système au matériel qui correspond à ses contraintes de synchronisation, à ses besoins en E/S et à ses objectifs de validation.
La gestion de la commutation à haute fréquence dans la simulation EMT en temps réel se résume à un choix technique difficile : le comportement du convertisseur le plus rapide doit être pris en charge par le matériel FPGA, tandis que le reste du système ne doit être géré par le CPU que lorsque le budget de pas de temps reste confortable. Ce choix revêt aujourd’hui une importance accrue, car les capacités renouvelables ont augmenté de 50 % en 2023 pour atteindre près de 510 GW, ce qui signifie que davantage d'équipements à convertisseurs sont intégrés aux réseaux, aux entraînements, aux systèmes de stockage et aux bancs d'essai.
Vous pouvez toujours exécuter des modèles EMT volumineux en temps réel, mais seulement si vous cessez de traiter chaque sous-système comme s'il nécessitait le même traitement numérique. Les commutations rapides, le nombre élevé de convertisseurs et les tests de contrôleurs en boucle fermée mettent à rude épreuve les structures de modèles génériques. Le cas Harvest le montre clairement ce phénomène aux pages 2 à 5, où le nombre élevé de commutateurs, les exigences de synchronisation fine et l’exécution mixte sur CPU et FPGA sont tous traités comme des contraintes pratiques plutôt que comme des détails de modélisation abstraits.
Les performances de la simulation en temps réel dépendent des choix d'architecture de calcul
Les performances EMT en temps réel dépendent d'abord de l'architecture, puis du niveau de détail du modèle. Vous ne respecterez pas les délais si le solveur, le pas de temps et la cible matérielle ne correspondent pas au comportement de commutation que vous essayez de reproduire.
Il convient de considérer le choix de l'architecture comme une question de timing, et non comme une préférence logicielle. Un processeur est idéal lorsque la densité des événements reste modérée et que le partitionnement est clair. Dès lors que les événements s'accumulent sur de nombreux sous-modules et que la gestion des temps morts devient cruciale, la plateforme d'exécution plateforme le principal paramètre de modélisation. Les équipes qui négligent cet aspect passent généralement des semaines à régler un solveur qui n'était pas adapté à la charge de travail.
La simulation par processeur permet d'adapter des modèles de systèmes de grande envergure présentant une dynamique de commutation modérée

La méthode EMT sur processeur donne les meilleurs résultats lorsque l'on privilégie la portée à la granularité de commutation. Les grands réseaux électriques, les transformateurs, les composants passifs et les sections de convertisseurs à commutation lente se prêtent généralement bien aux solveurs sur processeur.
Dans une étude de cas, le côté redresseur ne nécessitait pas de commutation à haute fréquence, de sorte qu'un pas de temps de l'ordre de quelques dizaines de microsecondes suffisait. Le solveur CPU restait toutefois essentiel, car il découplait plus de vingt convertisseurs d'un transformateur à enroulements multiples et maintenait le modèle dans les limites du temps réel sans ajouter de FPGA supplémentaire.
C'est la bonne façon d'utiliser les ressources du processeur. Vous les affectez aux parties du modèle qui sont volumineuses sur le plan numérique, mais qui ne comportent pas une forte densité d'événements. Vous gagnez également en flexibilité pour mener des études de réseau à plus grande échelle, configurer des défaillances et étendre l'installation. Les problèmes commencent lorsque vous demandez au processeur de reproduire chaque transition de porte, chaque intervalle de temps mort et chaque événement de commutation déphasé dans une pile de convertisseurs qui nécessite clairement une résolution bien plus fine.
La simulation basée sur un FPGA prend en charge des pas de temps de l'ordre de la nanoseconde et des modèles à haute fréquence de commutation
L'exécution sur FPGA est la solution idéale lorsque la gestion des transitions est au cœur du modèle, et non un simple effet secondaire. Elle offre une synchronisation déterministe et des pas de temps extrêmement courts, que les processeurs ne peuvent pas gérer dans le cadre d'échéances en temps réel.
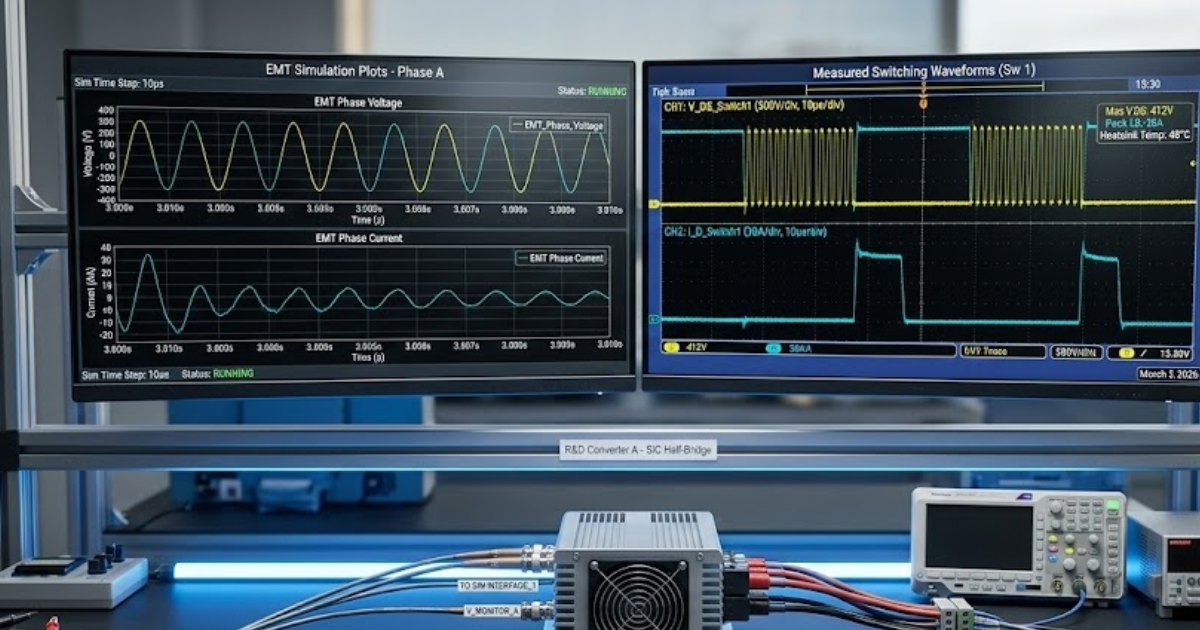
La page 4 du dossier indique que la boîte à outils d'électronique de puissance basée sur un FPGA prend en charge des fréquences de commutation supérieures à 200 kHz et des pas de temps de l'ordre de la nanoseconde. Cela est important pour les branches de convertisseur rapides, le comportement détaillé de la modulation d'impulsions en largeur (PWM) et les interactions entre composants qui disparaissent lorsque l'on augmente la taille du pas de temps. Un onduleur à pont en H en cascade ou un convertisseur SiC à grande vitesse en est un bon exemple, car la synchronisation des fronts détermine le résultat électrique.
Des travaux récents en laboratoire reflètent également cette même contrainte liée au matériel. Une étude du NREL souligne que la plupart des convertisseurs de forte puissance fonctionnent à une fréquence de commutation comprise entre 10 kHz et 50 kHz, ce qui impose déjà une forte contrainte sur la synchronisation du solveur en temps réel, avant même d’y ajouter des déphasages à plusieurs niveaux ou la logique de gestion des défauts.
« La gestion de la commutation à haute fréquence dans une simulation EMT en temps réel se résume à un choix technique difficile : le comportement du convertisseur le plus rapide doit être pris en charge par le matériel FPGA, tandis que le reste du système ne doit être géré par le processeur que lorsque le budget de pas de temps reste suffisant. »
Le comportement de commutation de l'électronique de puissance détermine souvent à quel moment il devient nécessaire d'utiliser un FPGA
C'est le comportement de commutation, et non la taille du modèle à elle seule, qui détermine quand il devient nécessaire de recourir à un FPGA. Le principal facteur déclencheur réside dans les événements de commutation denses et répétés dont l'erreur de synchronisation peut altérer la réponse de commande, les pertes, les harmoniques ou la logique de protection.
Pour un exemple de seuil, chaque sous-module en pont complet commutait à une fréquence comprise entre 500 Hz et 1 000 Hz, mais le déphasage entre les différents niveaux et le temps mort de la modulation d'impulsions (PWM) ont fait grimper la fréquence de commutation effective par phase jusqu'à 10 kHz. C'est exactement le genre de situation où un modèle peut paraître simple sur le papier, mais s'avérer difficile à mettre en œuvre.
Il convient de surveiller trois signes avant-coureurs. Premièrement, de légères erreurs de synchronisation commencent à altérer la forme des signaux. Deuxièmement, plusieurs cellules du convertisseur commutent de manière décalée, ce qui multiplie la fréquence des événements. Troisièmement, les fonctions de protection et de contrôle reposent sur la reproduction de ces événements sans gigue. Dès l'apparition de ces signes, le FPGA n'est plus un simple choix d'optimisation. Il devient le seul moyen fiable de garantir une synchronisation précise.
Modéliser des stratégies de partitionnement qui combinent efficacement l'exécution sur CPU et sur FPGA
Les meilleurs systèmes EMT en temps réel ne chargent pas un seul type de processeur de tout faire. Ils divisent le modèle de manière à ce que chaque processeur traite les aspects physiques qu'il est capable de résoudre avec précision, dans les limites de son propre temps de calcul.
Un variateur moyenne tension en est un bon exemple. La partie onduleur, avec ses commutations fréquentes et ses exigences strictes en matière de temps mort, doit être gérée par le FPGA. Le redresseur, le couplage par transformateur et les dynamiques de réseau plus lentes peuvent rester sous la responsabilité du CPU lorsque leurs besoins de calcul se situent de l'ordre de la microseconde. C'est exactement la répartition mise en évidence dans cette étude, où le FPGA gère la partie liée au convertisseur, tandis que le CPU prend en charge la structure électrique, plus vaste mais plus lente.
Une plateforme qu'OPAL-RT revêt ici une importance particulière, car le flux de travail ne se résume pas à une simple question de vitesse brute. Il faut une gestion des E/S fluide, une exécution synchronisée et un moyen pratique d'étendre le modèle lorsque le nombre de convertisseurs augmente. Un mauvais partitionnement engendre davantage de difficultés au niveau de l'interface qu'il n'apporte de soulagement au solveur ; la frontière entre le CPU et le FPGA doit donc suivre le comportement de commutation, et non les habitudes organisationnelles.
| Situation que vous modélisez | Un choix d'exécution qui garantit la fiabilité en temps réel | La principale raison pour laquelle ce choix tient la route |
| Un vaste réseau comprenant des lignes, des transformateurs et une activité modérée au niveau des convertisseurs | Maintenez la majeure partie de la plante sur le CPU en utilisant un pas fixe plus grossier | Le nombre de commutations est suffisamment limité pour que le processeur puisse consacrer ses ressources à l'évolutivité du réseau et à l'interconnexion |
| Une branche de convertisseur caractérisée par une fréquence élevée d'événements PWM et une grande sensibilité au temps mort | Transférer cette section de conversion vers l'exécution sur FPGA | La résolution temporelle doit rester déterministe à un niveau bien inférieur à celui que le processeur peut généralement maintenir |
| Un circuit d'attaque à plusieurs niveaux avec commutation décalée sur de nombreuses cellules | Répartir les cellules de l'onduleur rapide sur le FPGA et laisser les blocs de support plus lents sur le processeur | La densité des événements augmente plus rapidement que la taille du modèle ; l'exécution mixte permet ainsi d'éviter de gaspiller une résolution fine sur les sous-systèmes lents |
| Un banc d'essai pour contrôleurs avec codeur et retour d'information du moteur en boucle fermée | Conserver l'interface rapide de l'installation sur le FPGA et placer les sections plus lentes de l'installation sur le processeur | Les erreurs de synchronisation en boucle fermée apparaissent rapidement lorsque les signaux des capteurs et de commutation sont retardés ou soumis à des fluctuations |
| Un système de laboratoire à coût limité qui nécessite néanmoins une large couverture végétale | Réservez les ressources du FPGA uniquement pour les sections qui en ont réellement besoin | Le placement sélectif préserve la fidélité là où cela compte et évite de payer pour un synchronisme précis sur l'ensemble du modèle |
Les contraintes liées au coût, à l'évolutivité et à l'intégration qui déterminent les choix architecturaux
Les choix architecturaux sont d'ordre technique, mais ils restent influencés par les contraintes budgétaires et celles liées aux laboratoires. L'objectif n'est pas de tout intégrer dans le FPGA. L'objectif est de ne consacrer une synchronisation précise qu'aux endroits où cela modifie le résultat du test.
Les détails matériels présentés à la page 3 montrent comment cela se traduit concrètement. Le simulateur qui y est décrit prend directement en charge les topologies de ponts complets triphasés comportant de 8 à 13 ponts en cascade, tandis que les topologies de niveau supérieur utilisent la communication par fibre optique pour les signaux de commutation et les mesures. Cela signifie qu'une évolutivité est possible, mais uniquement si votre plan d'E/S et votre schéma de synchronisation sont conçus dès le départ.
Il convient également d'inclure les coûts d'intégration dans le coût global du modèle. Une capacité FPGA supplémentaire, le conditionnement des signaux, les interfaces de codeurs et les liaisons par fibre optique s'avèrent rentables lorsqu'ils permettent d'éliminer les risques liés au prototypage ou de raccourcir la phase de validation des commandes. En revanche, ils ne se justifient pas pour chaque modèle de redresseur, de filtre ou d'alimentation. De bons choix architecturaux permettent de limiter l'extension matérielle aux besoins réels en matière de synchronisation, et non à une vague aspiration à une fidélité maximale en toutes circonstances.
Erreurs courantes de modélisation qui empêchent les simulations sur CPU de respecter les délais en temps réel
Les modèles EMT en temps réel pour processeurs échouent généralement à cause d'un petit ensemble d'erreurs récurrentes. La plupart de ces erreurs proviennent du fait d'imposer un niveau de détail uniforme à des sous-systèmes qui ont des exigences de synchronisation très différentes.
Une analyse pratique de la Harvest met en évidence cinq erreurs qui reviennent souvent :
- Attribuer le même pas de temps fin aux branches de convertisseur rapides et aux sections de réseau lentes
- Maintenir les blocs de transformateur et de convertisseur étroitement couplés au sein d'une seule tâche CPU non partitionnée
- La modélisation de chaque événement de commutation sur le processeur après le déphasage multiplie le nombre d'événements
- Considérer les données de retour des capteurs et des moteurs comme secondaires, même lorsque le test est en boucle fermée
- Augmenter le nombre de cellules du convertisseur sans remettre en cause les contraintes de synchronisation et de timing des E/S
Une équipe chargée de développer un modèle d'entraînement en cascade se heurtera rapidement à ces limites. La page 5 explique pourquoi l'exécution à plusieurs vitesses et le découplage sont essentiels, tandis que la page 2 montre à quelle vitesse le nombre de commutations et le couplage augmentent. Le non-respect des délais n'est généralement pas le signe que l'EMT est impossible. Il indique plutôt que l'architecture du modèle est restée générique alors que le problème de commutation avait cessé de l'être.
« Un mauvais partitionnement cause plus de problèmes d'interface qu'il n'apporte de solutions ; la frontière entre le CPU et le FPGA doit donc suivre le comportement de commutation, et non les habitudes organisationnelles. »
Les plateformes hybrides associant CPU et FPGA offrent des performances évolutives pour les essais HIL complexes
Les plateformes hybrides constituent la solution la plus efficace pour les travaux HIL complexes, car elles adaptent la méthode de calcul au comportement électrique. C'est pourquoi le partitionnement rigoureux continue de l'emporter sur l'ambition d'une solution entièrement CPU et sur les excès d'une solution entièrement FPGA.
La preuve la plus convaincante est d'ordre pratique, et non théorique. Les pages 5 et 6 présentent une configuration dans laquelle des modèles numériques de moteurs et de capteurs ont remplacé les essais physiques risqués pour la vérification des commandes, les contrôles de défaillance, les essais multi-moteurs et la reproduction des problèmes. Ces gains ont été obtenus en concentrant les opérations de commutation rapide là où elles devaient l'être, en optimisant les sections plus lentes en fonction des coûts et en intégrant les contraintes de synchronisation dès le début de la conception.
C'est la norme que vous devriez appliquer à votre propre banc d'essai. Une exécution hybride propre vous évite de surdimensionner la plateforme de sous-modéliser le convertisseur. OPAL-RT s'inscrit naturellement dans cette logique, car l'intérêt ne réside pas uniquement dans le matériel. L'intérêt réside dans un flux de travail qui vous permet de placer la commutation EMT rapide sur le FPGA, de conserver les sections plus larges de l'installation sur le CPU et d'obtenir des résultats HIL reproductibles sans avoir à deviner.
Des solutions en temps réel dans tous les secteurs
Découvrez comment OPAL-RT transforme les secteurs les plus avancés du monde.

Systèmes d'alimentation
25/07/2026
Pourquoi les relais de protection à distance se déclenchent-ils de manière erronée en cas de défaut réel ?
Cet article explique pourquoi les relais de protection à distance peuvent présenter des erreurs de portée en cas de résistance de défaut, d'alimentation de la source, de transitoires liés aux transformateurs de tension capacitifs et de transfert important, et comment les essais par simulation permettent de vérifier la portée des zones avant la mise sous tension.

Systèmes d'alimentation
23 juillet 2026
Automatisation des tests de conformité aux codes de réseau pour les centrales équipées d'onduleurs
Les essais de conformité aux codes de réseau pour les parcs d'onduleurs s'appuient sur des études de réseau fragile, des définitions fixes des perturbations, des séquences scriptées reproductibles et des critères structurés de réussite ou d'échec.

Électronique de puissance
22 juillet 2026
Tester les commandes du convertisseur en toute sécurité avant de brancher le matériel
Cette page explique comment l'injection de défauts, les modèles d'installations en boucle fermée et les contrôles de récupération permettent de valider les commandes des convertisseurs avant leur raccordement au matériel.