
当人工智能每年消耗的电量超过全国部分地区的能源消耗总量时,会发生什么?是的,我们说的是每年大约数十万兆瓦时。预计人工智能将占数据中心电力需求的 20%左右。
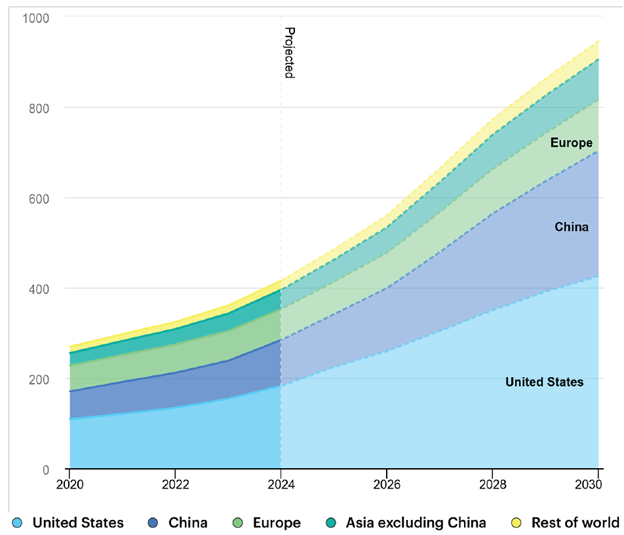
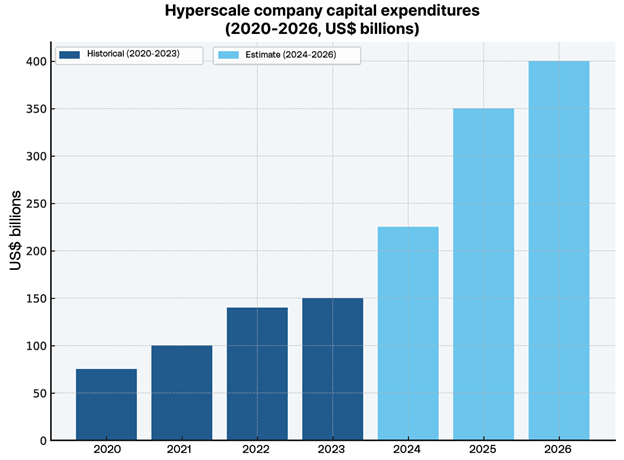
以人工智能为重点的数据中心的激增推动了电力需求的增长。预计到 2030 年,数据中心的用电量将增加一倍以上,从 2024 年的 415 太瓦时增加到 945 太瓦时以上,成为发达经济体中电力负荷增长最快的来源之一。扩大人工智能规模的竞赛不再只是为了训练更大的模型,而是为了能源。数据中心曾经是数字经济中沉默的脊梁,如今却成为全球能源辩论的焦点。高盛研究预测,2025 年和 2026 年,美国五大超大规模企业的资本支出总额将达到 7360 亿美元。这不仅是一个统计数据,更是一记警钟。
隐藏的挑战:人工智能工作负载的功率波动
大型人工智能训练工作负载的电源管理问题涉及数以万计的 GPU。传统的谷歌搜索耗电量约为 0.3 瓦时(Wh);然而,采用人工智能功能(如 ChatGPT 或谷歌人工智能驱动的响应)的查询耗电量可高达十倍,从 2.9 瓦时到 3.6 瓦时不等,具体取决于所采用的任务和模型。据 Axios 报道,谷歌每小时处理约 5.71 亿次搜索(≈每秒 158548 次),而仅 ChatGPT 每小时就处理约 1.04 亿次提示(≈每天 25 亿次)。这些巨大的能源足迹并非集中在一个地方,而是分布在全球数百个超大规模和企业数据中心,每个数据中心都运行着庞大的服务器和 GPU 机群。这意味着,即使总体查询次数较少,人工智能驱动搜索的能源足迹也会迅速超过传统搜索。人工智能搜索的能耗增加是由于生成式人工智能模型需要进行复杂的计算,而传统搜索的信息检索较为简单。
电网稳定性受到威胁
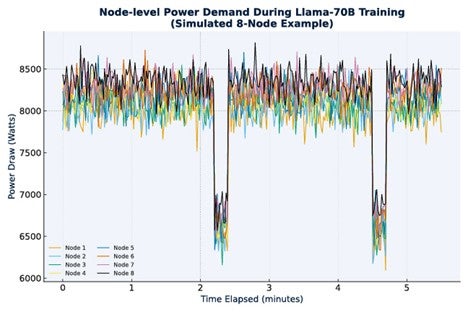
在计算密集型阶段,每个 GPU 都要处理本地数据,而在通信密集型阶段,所有 GPU 都要同步处理数据,因为这些工作是同步进行的。由于计算密集型阶段比通信密集型阶段耗电量大得多,因此会出现较大的功率波动。随着训练作业数量的增加,这些功率波动的幅度也会增加。这些功率波动的频率范围带来了更大的困难(如图 3 中 Llama 的情况所示),因为如果它与电力公司的基本频率相吻合,就有可能对电网基础设施造成物理破坏。因此,我们需要稳定此类工作负载的功率。
典型的数据中心负载:冷却、备用和复杂的电力电子设备
每个数据中心都包含多个服务器,因此在处理数据时会产生大量热量。这些服务器的运行和冷却是耗电的主要原因之一。
能源使用量大、运行需求波动大、冷却需求大是这些负载的特点。负载的内部配置(包括备用电源和内部保护)可能极其复杂。由于数据中心和其他计算需求经常出现在电力价格低廉且可靠的地方,因此需要严格的电网规划和连接技术。由于大规模负载将逐渐主导未来的电力系统,因此主要的挑战是如何积极主动地解决这些困难,从而更好地了解电网的动态。

同样重要的是,该行业仍然缺乏明确的规定和标准化的方法来模拟和整合如此复杂的负载,这使得数据的获取和一致性成为规划者和研究人员面临的日益严峻的挑战。
对于数据中心来说,面临的挑战是多个组件在非常不同的时间尺度上相互作用:保护系统、电力电子设备、控制器和能源管理系统(EMS),特别是因为大多数数据中心都依赖于 UPS 设备或发电机等备用电源。换流器 内部的快速切换以微秒为单位,而保护系统和穿越行为则以毫秒为单位。
测试所有这些系统之间的相互作用至关重要,这不仅是为了验证当前的设计,也是为了探索有助于减轻电网影响的新控制方法和技术,如 E-STATCOM、削峰或无功补偿。硬件在环(HIL)仿真 使测试这两端成为可能。基于 FPGA 的工具可捕捉整流器、逆变器和固态变压器的超快开关谐波,而基于 CPU 的求解器则可处理较慢但同样重要的行为,如电压稳定性和故障穿越。将这些工具结合起来,就能验证数据中心的内部系统如何与更大的电网互动,确保冷却、备用电源和复杂的电子负载即使在压力下也能保持稳定。
随着数据中心规模和复杂性的不断扩大,它们对全球能源系统的影响不容忽视。巨大的电力需求、波动的负载和大量的冷却要求,这些因素的结合凸显了对更智能的电网规划和创新工程解决方案的迫切需求。通过采用实时仿真、先进建模和更高效的基础设施设计,该行业可以确保数据中心继续成为可靠、可持续和有弹性的数字经济基石。

