
Key Takeaways
- Real time HIL validation matters because embedded control quality depends on timing, I/O behaviour, and plant interaction, not only on correct control logic.
- The most useful HIL setups focus on deterministic execution, credible plant models, representative interfaces, and repeatable fault scripts.
- Verification cycles shrink when teams use digital plant models for structured fault coverage and reserve physical hardware for targeted confirmation.
Control algorithm validation using real-time HIL starts with one practical truth: you will not know if a controller is ready until it runs against time-accurate plant behaviour, real input/output signals, and repeatable fault cases. Bench testing with physical hardware comes too late and costs too much when timing faults, protection gaps, or sensor-handling errors surface after code is already tied to a prototype.
That need is getting harder to ignore as control software spreads across power conversion, motion control, and electrified equipment. NHTSA recorded 74 electric vehicle recalls affecting 2,911,154 vehicles in 2024, which shows how software-linked control issues now land at production scale instead of staying in the lab.
How hardware-in-the-loop testing validates control algorithms before hardware deployment
Hardware-in-the-loop validates control algorithms by placing the actual controller in a closed loop with a simulated plant that runs with deterministic time steps. You test the controller against realistic system response before full power hardware, full mechanical assemblies, or final prototypes are ready.
A motor drive team gives a clear example. The controller can read simulated current, voltage, speed, and encoder signals while the plant model responds to gate commands, load steps, and protection logic as if a live machine were present. The Harvest case shows this approach used to verify control strategies for asynchronous and permanent magnet synchronous motor applications while reducing dependence on physical test assets.
That matters because algorithm validation is not just about correct maths. It is about timing, saturation, measurement noise, state transitions, and what the controller does when the plant stops behaving nicely. HIL gives you repeatability on those conditions, which means failures become diagnosable instead of anecdotal. You can rerun the same event, compare traces, and fix root causes before hardware risk enters the picture.
Why software simulation alone cannot verify embedded control performance
Software simulation alone cannot verify embedded control performance because it does not fully expose the timing, interface, and execution constraints of the physical controller. A model that looks stable on a workstation can misbehave once it meets fixed-step execution, field I/O latency, interrupt scheduling, and quantized sensor signals.
A common case appears in inverter or drive control. The control law works in an offline model, yet the embedded target drops samples during a fast transient, clips an internal variable, or misreads an encoder edge at the exact moment torque demand changes. Those faults stay hidden until the code runs on the controller hardware with the same interfaces it will use in service.
The Harvest case study is useful here because the testing challenge was not limited to converter logic. It also included multiple motor types and sensor models, such as incremental encoders, which means validation had to cover plant dynamics and controller interfacing at the same time. Software simulation is still important for early design work, but it will not settle the question that matters most: how the embedded controller behaves when computation, I/O, and plant response all interact under clocked execution.
Key requirements for reliable real-time control algorithm validation

Reliable real-time control algorithm validation depends on deterministic execution, credible plant models, representative I/O, and a test plan that covers nominal and abnormal operating states. If any one of those pieces is weak, your pass result will not mean much.
You can check the essentials with this short list:
- Fixed time steps must match the control problem and switching behaviour.
- Plant models must reproduce the dynamics that shape controller response.
- Sensor and actuator interfaces must mirror deployed signal paths.
- Fault cases must include protection events and limit conditions.
- Logging must capture enough detail to explain failures quickly.
The Harvest case makes these requirements concrete. They needed support for several motor models, sensor types, and a converter topology with high computational load, so the test setup had to match both fidelity and execution speed. Teams often fail here by over-investing in model detail while under-investing in timing discipline or I/O realism. A useful HIL setup is not the most complicated one. It is the one that reproduces the controller’s true operating conditions with enough fidelity to expose the wrong decisions.
| What you need to check | Why it matters in practice |
| Time step selection must reflect plant speed and controller cycle time | A controller can look stable at a loose step size and fail once switching events and fast state changes are resolved properly. |
| Plant fidelity should match the control objective | Current loops, speed loops, and protection logic each fail for different reasons, so the model has to represent the behaviour that those loops actually see. |
| I/O mapping must match deployed signals | Incorrect scaling, filtering, and interface timing create false confidence long before code reaches the bench. |
| Fault scenarios should be scripted and repeatable | Repeatable faults turn debugging into engineering work instead of trial and error. |
| Traceability between tests and waveform logs must stay intact | You need to know exactly which condition exposed a defect so fixes can be verified with confidence. |
How engineers build closed-loop HIL test systems for embedded controllers
Engineers build closed-loop HIL systems by linking the controller to a plant model that runs in real time, then wiring every important signal path so the controller sees believable measurements and the simulator sees genuine commands. The system only works when timing and interfaces are treated as part of the plant.
A drive control setup is a good illustration. The simulator computes converter, transformer, motor, and load response at fixed time steps. The embedded controller sends switching or modulation commands back to the simulator, while analogue, digital, or encoder channels feed measured states into the controller. Each loop closes on the next real-time tick, not on a best-effort software schedule.
The Harvest deployment described in the file used a scalable simulator with large I/O capacity and fibre communication for higher-level topologies, which shows how closed-loop design expands as converter count and signal volume rise. Teams usually get faster results when they start with one validated loop, such as current control, then add speed control, protections, and supervisory logic in sequence. That staged build keeps timing problems visible instead of hiding them inside a huge first-pass integration.
Reproducing faults and edge cases that expose hidden control defects
Fault reproduction is where HIL earns its keep because it lets you run dangerous, rare, or expensive events as often as needed.
“Hidden control defects usually appear at transitions, limit crossings, and protection boundaries rather than during steady operation.”
A medium-voltage drive example makes that plain. You can inject bus overvoltage, undervoltage, phase loss, grounding faults, or out-of-phase conditions without risking people or hardware. The Harvest case reports protection testing for synchronous switching cases, single-phase output grounding, out-of-phase detection, and bus voltage faults, all on the HIL bench instead of a hazardous full-power setup.
That approach improves coverage and learning speed. NIST reported that combinatorial testing can achieve fault detection close to exhaustive testing with a 20x to 700x reduction in test suite size, which is a strong reminder that structured variation matters more than random test growth. A good HIL campaign reflects that lesson. You do not need thousands of loosely chosen scenarios. You need the right combinations of setpoint shifts, sensor faults, operating modes, and protection triggers that stress the controller where interaction faults actually live.
Using digital plant models to replace motors sensors and power hardware
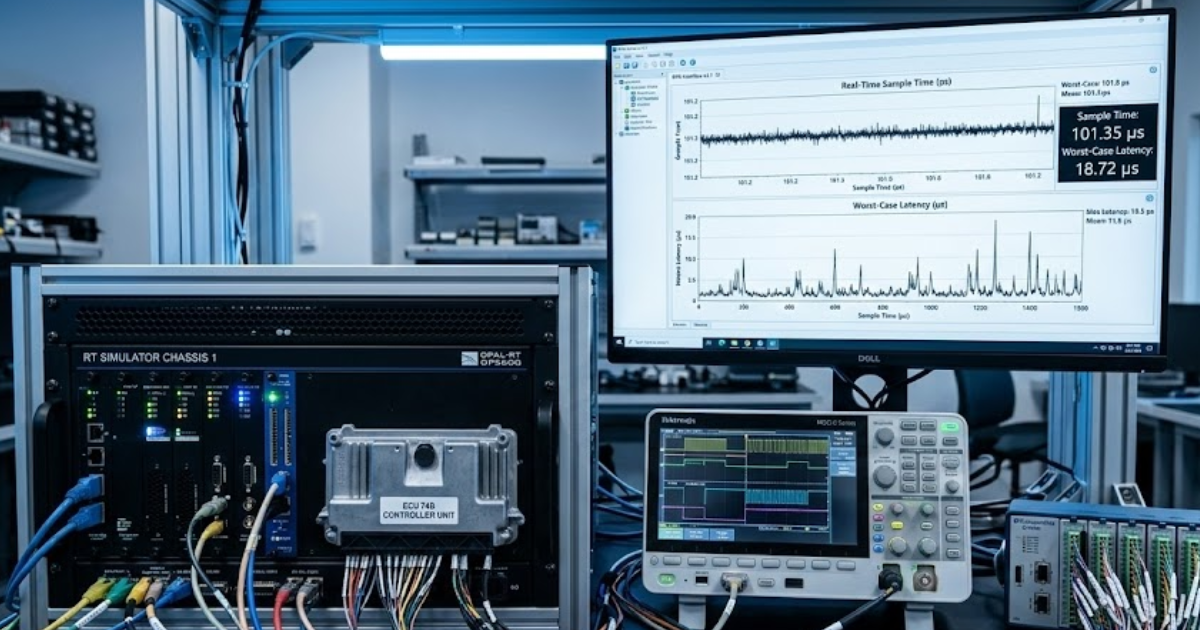
Digital plant models replace motors, sensors, and power hardware when the controller needs realistic behaviour more than it needs physical equipment. That shift cuts cost, shortens setup time, and lets you test plant variants that would be difficult to assemble on demand.
A single HIL bench can stand in for an induction motor in one session and a permanent magnet synchronous motor in the next. The attached case also points to encoder and resolver style feedback, which matters because control code often fails at the interface between estimated states and measured states rather than inside the main control law.
The benefit is not abstraction for its own sake. It is control over the test space. You can adjust inertia, load torque, sensor resolution, or converter conditions without rebuilding a rig. High-speed switching components often run on FPGA-based solvers while slower electrical network sections run on CPU-based solvers. This separation keeps simulation stable at small time steps while preserving computational efficiency. That kind of partitioning keeps the digital plant useful for validation instead of turning it into a simplified demo that misses the behaviour your controller must survive.
Integrating real-time simulators with controller hardware and I/O systems
Real-time simulator integration succeeds when signal integrity, timing alignment, and interface mapping are treated as engineering tasks instead of cabling tasks. The controller must see the same signal types, scaling, and update behaviour it will receive in deployed operation.
Picture a controller that expects encoder pulses, fast analogue feedback, digital interlocks, and trip inputs. If the simulator feeds clean values with no realistic latency or scaling, the code will pass under conditions that never exist on a real cabinet. The Harvest setup addressed this problem with substantial analogue and digital I/O capacity, front and rear monitoring connections, and expansion paths for larger communication loads.
Integration work also includes open-loop checks before closed-loop runs. Signal polarity, unit conversion, threshold logic, and task scheduling errors are much easier to fix before the loop closes. That preparation step is easy to rush past, yet it is one of the best ways to avoid chasing false controller faults that are really interface faults. Strong HIL practice treats wiring, scaling, and scheduler timing as part of control validation because that is exactly what they are.
Engineering practices that shorten control algorithm verification cycles
“Control algorithms become dependable through repeated exposure to realistic timing, interfaces, and fault conditions, not through confidence in a clean model or a single bench pass.”
Shorter verification cycles come from disciplined test design, staged integration, and rapid feedback on waveform evidence. Teams move faster when each HIL run answers a specific control question and feeds directly into the next code change.
A strong pattern is easy to spot in the attached case: reproduce site issues in the lab, verify protection logic under fault, reuse one bench for multiple motor types, and expose code defects early enough that fixes do not wait on hardware access. That is why HIL changes the tempo of control work. It turns scarce prototypes into confirmation tools instead of discovery tools.
The lasting judgement is simple. OPAL-RT appears naturally in that picture because the work is about execution: matching computation method to plant speed, connecting controller I/O without distortion, and keeping tests repeatable enough that every fix proves something useful.
Real-time solutions across every sector
Explore how OPAL-RT is transforming the world’s most advanced sectors.

Simulation
03 / 27 / 2026
Real-time simulation for validating autonomous and ADAS systems
Explains why autonomous and ADAS validation relies on deterministic real-time simulation and hardware-in-the-loop, what scenarios matter, how to assess simulator stacks, and where simulation programs commonly fail.

Simulation
03 / 25 / 2026
Integration testing between firmware and physical interfaces
Covers how to plan and run firmware integration testing for physical interfaces using staged loops, HIL protocol simulation, tool selection, and trace-based debugging for CAN and similar buses.

Industry applications, Simulation
03 / 25 / 2026
Real-time simulation of multilevel converters and cascaded topologies
A practical guide to multilevel converter simulation that explains how cascaded H bridge models are partitioned across CPU and FPGA resources for accurate real-time EMT and hardware in the loop testing.
EXata CPS has been specifically designed for real-time performance to allow studies of cyberattacks on power systems through the Communication Network layer of any size and connecting to any number of equipment for HIL and PHIL simulations. This is a discrete event simulation toolkit that considers all the inherent physics-based properties that will affect how the network (either wired or wireless) behaves.