7 ways simulation breaks down in autonomous vehicle testing and how to fix them
Automotive
08 / 06 / 2025

Every stalled prototype feels like a missed opportunity when you’re racing to make self‑driving technology safe. Programme milestones slip out of reach, funding confidence wobbles, and engineers scramble to explain why the test bench refuses to keep pace with design iterations. You feel pressure from managers who need proof that perception algorithms will not misclassify a pedestrian once the car leaves the proving ground. In that moment, simulation quality and test orchestration decide whether your next report highlights progress or delay.
Schedules tighten, but the complexity of today’s vehicle sensor suites keeps growing, pulling radar, lidar, cameras, and high‑performance compute into one fragile pipeline. An unexpected glitch within that pipeline can turn a week‑long regression cycle into a three‑week fire‑drill. Teams that tame this complexity secure faster sign‑offs, regain budget headroom, and boost credibility with regulatory partners. The rest keep adding patches until their test matrix becomes unmanageable.
Simulation quality and test orchestration decide whether your next report highlights progress or delay.

Common causes of testing delays in autonomous vehicle validation
Sensor fusion stacks, functional safety workflows, and cybersecurity verifications all pull on the same finite pool of hardware‑in‑the‑loop (HIL) rigs. This crowding creates scheduling friction that cascades into broader programme delays, exposing the challenges in autonomous vehicle testing and validation that plague many engineering teams. Each time a system under test waits for the bench, engineers risk losing context, which leads to re‑work and duplicate bug triage. Even when the rig becomes available, manual reconfiguration often wastes half a day before a single scenario can run.
Test momentum falters further when model fidelity lags behind design changes. Low‑resolution sensor emulation hides defects until track trials, causing expensive rework. File transfers between desktop design tools and HIL storage can consume hours, making overnight regression runs impossible. Add governance requirements for traceability across thousands of scenarios, and the queue becomes longer than the sprint itself.
7 common simulation challenges in autonomous driving projects
Precise and timely validation separates concept cars from production fleets. Engineers face mounting pressure from safety authorities, investors, and public sentiment, all of which demand credible evidence that autonomy functions work in complex traffic. Simulation promises near‑infinite mileage without physical prototypes, yet its effectiveness collapses when pipelines, models, or data management slip out of alignment. A closer look at these fractures reveals the most stubborn roadblocks and how disciplined workflows clear them efficiently.
1. Incomplete or low‑fidelity models reduce test coverage
Early‑stage perception models often rely on simplified kinematics or generic sensor error profiles. Those shortcuts feel acceptable until corner‑case crashes appear during closed‑course trials, forcing emergency fixes that distract from planned feature work. High‑resolution terrain meshes, detailed radar cross‑sections, and weather‑dependent noise layers help expose silent faults before track time begins. Maintaining that fidelity across multiple suppliers, however, proves difficult when file formats and versioning practices diverge.
Simulation datasets age quickly as design parameters shift, leading to misleading confidence metrics. Teams that adopt automated model validation pipelines catch stale assets before nightly builds start, preserving trust in key performance indicators. Clear ownership boundaries and modular interface specifications reduce hand‑off friction between system‑of‑systems contributors. Investment in scalable storage with robust metadata tags keeps retrieval time low without compromising granularity.
2. Toolchain integration issues cause test instability
Scripting glue that links closed‑source physics engines, custom middleware, and safety monitors often hides subtle latency spikes. Those spikes introduce non‑deterministic behaviour in closed‑loop runs, eroding confidence in timing‑dependent control logic. Engineers burn valuable days isolating an obscure buffer overrun rather than collecting coverage data. A disciplined integration strategy, anchored by open application programming interfaces (APIs) and code linting, prevents these disruptions from spreading across sprints.
When version mismatches arise, deterministic rollback procedures restore a known‑good baseline in minutes instead of hours. Continuous integration servers that compile, deploy, and smoke‑test each code push catch dependency conflicts before a formal campaign starts. Shared logging schemas simplify triage by aligning time stamps and sensor identifiers across subsystems. The net result is a repeatable, traceable test flow that satisfies both internal audits and external certification bodies.
3. Scenario generation lacks edge case diversity
Scenario libraries often skew toward comfortable driving conditions because data collectors park vehicles when weather deteriorates. Absence of fog, blowing snow, or atypical construction signage leaves perception algorithms dangerously under‑trained. Synthetic scenario generators promise variety, yet naïve randomisation still misses safety‑critical juxtapositions such as unprotected left turns on cresting grades. Engineers boost meaningful diversity by applying risk‑based weighting rooted in insurance claims and incident databases.
Once priority conditions are defined, parameterised templates systematically permute speed, positioning, and traffic density, multiplying coverage without bloating storage. Human‑review gates flag visually implausible scenes that would otherwise consume simulation cycles needlessly. Over time, analytics dashboards highlight scenario clusters with persistently high failure rates, guiding focused improvements rather than scattershot tuning. This feedback loop keeps scenario libraries lean yet potent.
4. Limited hardware‑in‑the‑loop scalability slows iteration
A single HIL rack may cost hundreds of thousands of dollars, tempting budget owners to limit deployments. As feature teams multiply, contention for bench time grows in direct proportion to backlog. Remote queuing helps, but latency penalties and security hurdles limit throughput gains. Virtual HIL instances executed on cloud field‑programmable gate array (FPGA) resources offer elasticity, yet integration‑test rework often stalls adoption.
Successful programmes partition workloads between deterministic low‑level control loops that must run on physical FPGA cards and higher‑latency perception workloads that can migrate to virtualised compute. Allocation rules codified within orchestration scripts maintain real‑time deadlines while maximising concurrency. Engineers then spin up short‑lived cloud replicas for regression sweeps, freeing on‑site rigs for high‑stakes final sign‑off. Cost‑tracking dashboards linked to account codes keep finance teams comfortable with pay‑as‑you‑go usage.
5. Real‑time simulation falls short under complex conditions
Autonomy trials impose heavy computational loads due to dense sensor meshes, physics‑based vehicle dynamics, and high‑order weather models. When frame times stretch beyond millisecond‑level tolerances, control loops destabilise, producing false negatives that waste debug cycles. FPGA acceleration mitigates this risk, yet partitioning instructions across heterogeneous processing units demands specialist skill. Engineers accelerate onboarding by adopting reference designs that map computational kernels to suitable silicon automatically.
Performance‑profiling tools integrated into the simulation stack flag hotspots long before they threaten schedule commitments. Adaptive level‑of‑detail (LOD) algorithms down‑scale peripheral scenery while preserving critical foreground precision. Regular stress‑test campaigns record worst‑case matrix sizes and propagate those metrics into resource‑planning dashboards. These practices keep frame times stable, supporting continuous integration of fresh sensor models and algorithm updates.
6. Data management challenges affect traceability and repeatability
Petabytes of lidar point clouds, high‑definition maps, and telemetry logs overwhelm ad‑hoc folder structures. When naming conventions drift, engineers struggle to trace a regression to its original scenario definition. Audit requirements for functional safety certifications magnify the pain, as each dataset must map to specific requirements and pass–fail criteria. Adopting version‑controlled object stores with immutable record identifiers prevents silent overwrites that derail compliance reviews.
Petabytes of lidar point clouds, high‑definition maps, and telemetry logs overwhelm ad‑hoc folder structures.
Automatic metadata harvesting tags each simulation artefact with parameter hashes, software commit IDs, and hardware bill‑of‑materials references. Query engines built atop these tags return provenance chains in seconds, supporting root‑cause analysis and recall investigations. Role‑based access controls protect sensitive data while permitting seamless collaboration across globally dispersed teams. Together these practices foster trust that every metric on the dashboard reflects the correct input conditions.
7. Time‑consuming setup and reconfiguration of test benches
Hand‑wired sensor harnesses, manual power cycling, and spreadsheet‑driven configuration steps force engineers to stand idle between runs. A single connector mis‑seat can doom an overnight batch, consuming valuable daylight in re‑runs. Automating bench orchestration through scripted device configuration and digital twin alignment transforms hours of fiddling into minutes of repeatable routine. Modular fixture design further reduces physical re‑work by letting crews swap perception stacks without disturbing vehicle dynamics subsystems.
Configuration‑as‑code repositories capture every setup parameter, from sensor bias tables to FPGA bitstream versions. Continuous deployment frameworks push these configurations to HIL controllers, validating checksum integrity before execution starts. When a new hardware revision arrives, engineers update a YAML manifest rather than editing multiple spreadsheets, preserving institutional knowledge within version control. Predictable bring‑up times restore confidence that each sprint ends with validated results instead of lingering doubts.
The engineering gains unlocked by resolving these autonomous driving challenges reach far beyond the lab. Shorter regression cycles release teams to focus on feature innovation rather than firefighting. Improved traceability solidifies safety cases during regulatory submissions, accelerating time‑to‑market and strengthening brand reputation. Cost predictability improves capital planning, supporting strategic decisions about platform investment and staffing.
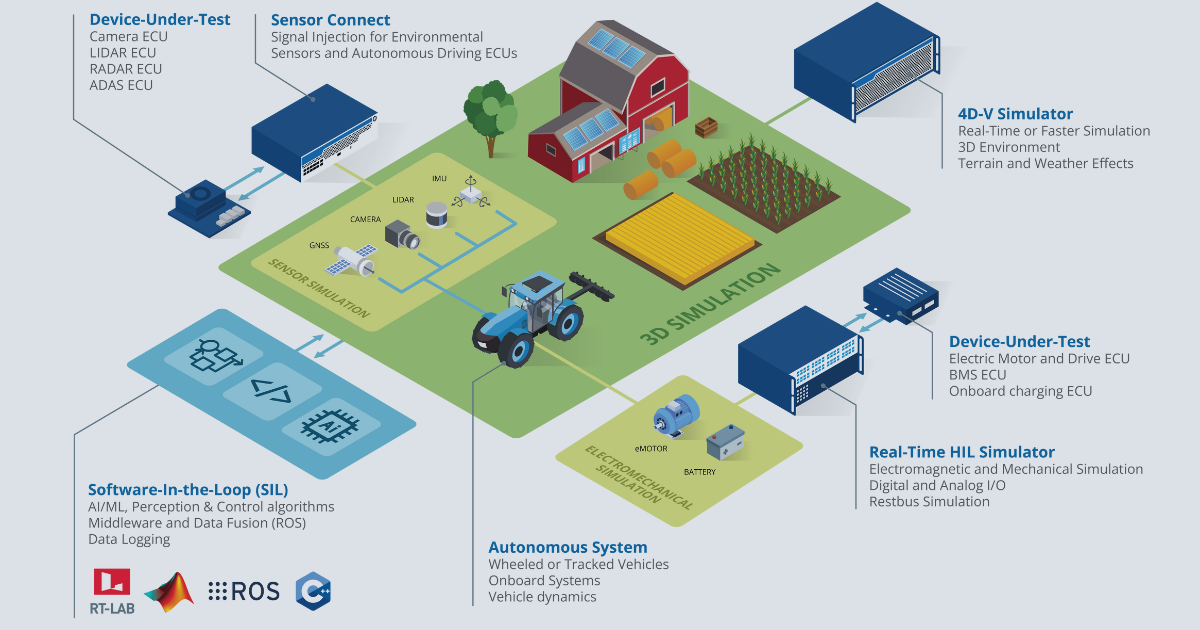
How are autonomous vehicles tested using real‑time simulation tools
Project teams start bench design by selecting deterministic execution engines capable of synchronising physics, sensor emulation, and control software within strict timing constraints. Hardware‑in‑the‑loop rigs host electronic control units (ECUs) and perception accelerators, while field‑programmable gate arrays enforce sub‑millisecond deadlines. Practitioners questioning how are autonomous vehicles tested quickly recognise that open interfaces matter as much as raw processing power, because model‑based design tools must hand off artefacts without data loss. Standardised functional mock‑up interface (FMI) packages and robot operating system (ROS 2) bridges keep that hand‑off clean, allowing heterogeneous subsystems to share simulation time stamps.
During execution, scenario servers stream digital road networks, traffic agents, and weather parameters into the simulation core. Synthetic sensor data passes through low‑level drivers to the actual ECU firmware, exercising the same stack destined for series production. High‑speed logging captures raw signals and algorithm decisions, feeding analytics dashboards that compare outcomes against key safety indicators. Engineers then refine perception thresholds, control gains, or fault‑handling logic and replay identical scenarios within minutes, locking down fixes before physical prototype budgets balloon.
How OPAL‑RT helps solve autonomous vehicle testing and validation challenges
OPAL‑RT brings high‑precision, low‑latency real‑time simulation platforms to engineers who refuse to compromise on timing accuracy or open architecture. Our modular hardware accommodates both CPU‑ and FPGA‑centric workloads, letting you match compute resources to each subsystem without wasting rack space or capital. The RT‑LAB software suite aligns MATLAB / Simulink, FMI/FMU, and Python assets within a single scheduling kernel, so you pass models between desktop design and hardware‑in‑the‑loop execution without format gymnastics. Integrated monitoring tools flag timing overruns instantly, giving your team clear insight into bottlenecks before they threaten safety targets. Licensing stays flexible, letting project leads align expenditure with sprint goals rather than committing to fixed‑capacity purchases.
Beyond performance, OPAL‑RT platforms bring peace of mind to autonomous vehicle testing and validation programmes. Immutable scenario identifiers, automatic metadata capture, and role‑based access controls satisfy rigorous functional safety audits. Native support for cloud‑burst execution extends HIL capacity during regression bursts, while local benches focus on final sign‑off runs. Global support staff include former simulation engineers who meet you in the lab or online, shortening diagnostic cycles and preserving momentum. You can trust OPAL‑RT to guard accuracy, budget discipline, and schedule confidence throughout every phase of autonomy development.
Common Questions
What are the biggest bottlenecks in autonomous vehicle testing workflows?
Test instability, scenario generation gaps, and data handling slow down validation cycles. Teams often struggle with incomplete models, slow HIL setup, and missing edge case coverage. These issues extend development timelines and lower confidence in software readiness. Solving them requires high‑fidelity simulation tools, open integration frameworks, and scalable infrastructure. OPAL‑RT provides real‑time simulation platforms that help eliminate these roadblocks and accelerate validation with precision.
How do I improve test coverage for edge cases in autonomous driving projects?
Expanding test coverage means going beyond common traffic scenarios to include high‑risk, low‑frequency situations like construction zones, inclement weather, or sensor interference. Teams can increase variation using parameterised templates and risk‑based weighting based on real incident data. Scenario diversity is key for building robust perception and control systems. OPAL‑RT supports high‑fidelity emulation with customizable scenario injection tools to strengthen your coverage with measurable control.
Why does hardware‑in‑the‑loop testing slow down during scale-up?
HIL test capacity often hits a wall when teams share a limited number of test benches across multiple projects. Without scalable infrastructure or virtual options, testing delays are inevitable. Cloud-based deployments and partitioning workloads across physical and virtual resources are vital. OPAL‑RT offers flexible deployment options that help increase throughput without compromising real‑time constraints, letting you scale without sacrificing quality.
How can I ensure repeatability and traceability across my simulation runs?
Managing terabytes of sensor data and test results becomes difficult without a structured data strategy. Versioned artefacts, metadata tagging, and configuration-as-code practices are necessary to link every test to its parameters. This clarity supports auditability and internal QA. OPAL‑RT’s platform captures full data provenance and scenario metadata to help teams meet certification standards while maintaining operational agility.
How are simulation tools used to validate autonomous vehicles?
Real‑time simulation tools replicate sensors, road networks, and system dynamics to stress-test autonomous vehicle systems under controlled conditions. These tools must interact with actual control hardware and mirror production workloads to give accurate performance feedback. Realism, timing precision, and openness to third‑party models are essential. OPAL‑RT delivers all three through its FPGA/CPU hybrid simulators, allowing you to iterate faster and validate safely.
Real-time solutions across every sector
Explore how OPAL-RT is transforming the world’s most advanced sectors.

Industry applications, Simulation
03 / 31 / 2026
Managing high-frequency switching in real-time EMT simulation
Precision in testing complex power systems is essential to avoid failures, accelerate innovation, and integrate new technologies safely.

Simulation
03 / 30 / 2026
Understanding timestep requirements for modern power converters
Practical criteria for selecting EMT and real time simulation timesteps for power converters, covering switching resolution, control and PWM timing alignment, multirate approaches, and verification checks.

Industry applications, Simulation, Energy
03 / 29 / 2026
Validating data center energy management systems using real-time HIL
This piece explains how AI workload variability affects data centre power stability and how closed-loop HIL testing helps validate EMS control behaviour under site and grid stress.
EXata CPS has been specifically designed for real-time performance to allow studies of cyberattacks on power systems through the Communication Network layer of any size and connecting to any number of equipment for HIL and PHIL simulations. This is a discrete event simulation toolkit that considers all the inherent physics-based properties that will affect how the network (either wired or wireless) behaves.